# 三、垃圾回收
# 如何判断对象可以回收
# 引用计数法
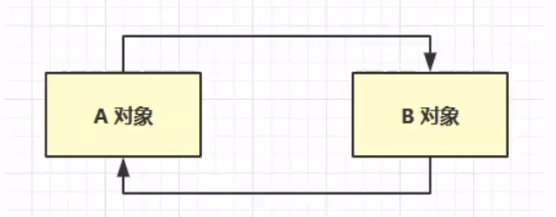
判断对象被引用的次数,看对象是否可以被回收。但是根据下面的互相调用的情况,此时A、B两对象互相引用,且引用次数为1的话,则不能根据引用次数对其进行垃圾回收(因为互相引用),但是长时间不对这两者对象进行垃圾回收,则会导致内存泄漏,长时间存在内存得不到释放的情况,所以引用计数法存在一定的弊端。在实际的虚拟机中,一般需要采用下面的可达性分析算法。
# 可达性分析算法
在此算法中,我们将那些一定不能被垃圾回收的对象称之为“根对象”。在进行垃圾回收之前,会对类中所有的对象进行一次扫描,看看其中的对象是否会被其中的根对象直接或间接引用。如果有引用,则该对象不能被垃圾回收,由于根对象的绑定关系,会导致该对象有需要被引用的可能,故不能被垃圾回收;反之,如果对象没有被根对象直接或间接引用,则该对象存在被垃圾回收的可能性。
以上这个过程被称之为可达性分析算法。但是,如何确定根对象(GC Root)?
要找到GC Root对象,我们需要借助一个Eclipse提供的工具——Memory Analyzer,简称MAT。

具体操作步骤:
先找出Java程序的进程ID,之后输入相关参数,生成二进制文件,抓取程序进程快照,之后利用工具打开生成的二进制文件 进行分析。
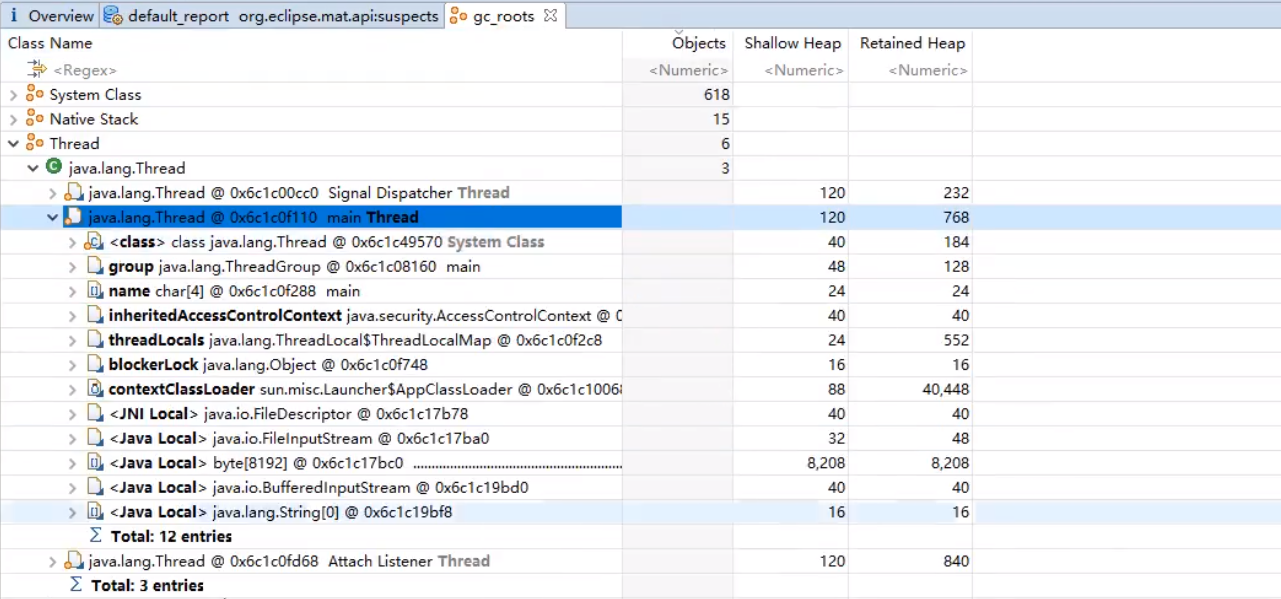
MAT工具打开文件之后,操作界面如下所示:
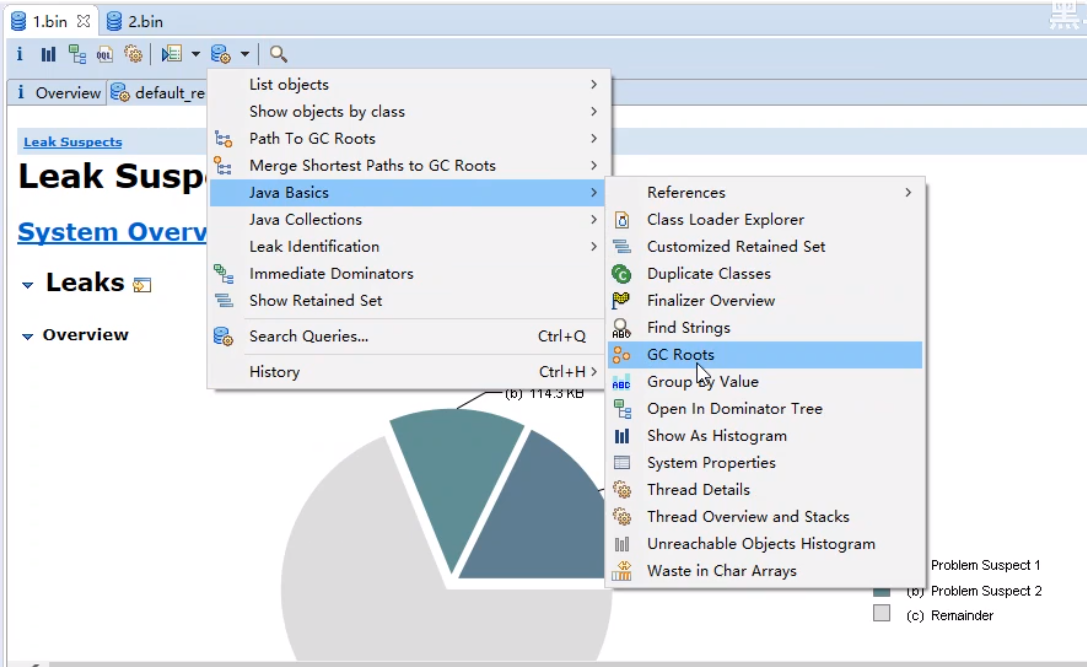
GC Roots显示的界面如下所示:
可知当前一共有641个对象。其中,System Class为系统核心类,不能被回收掉。
实际上的分析,只需要看主线程中的对象,查看哪些本地变量是GC Root对象,不能被回收。
# 四种引用
实际上常用的一共有五种引用。分别为:强引用、弱引用、软引用、虚引用、终结器引用。
引用示例图:(其中,实线表示强引用)
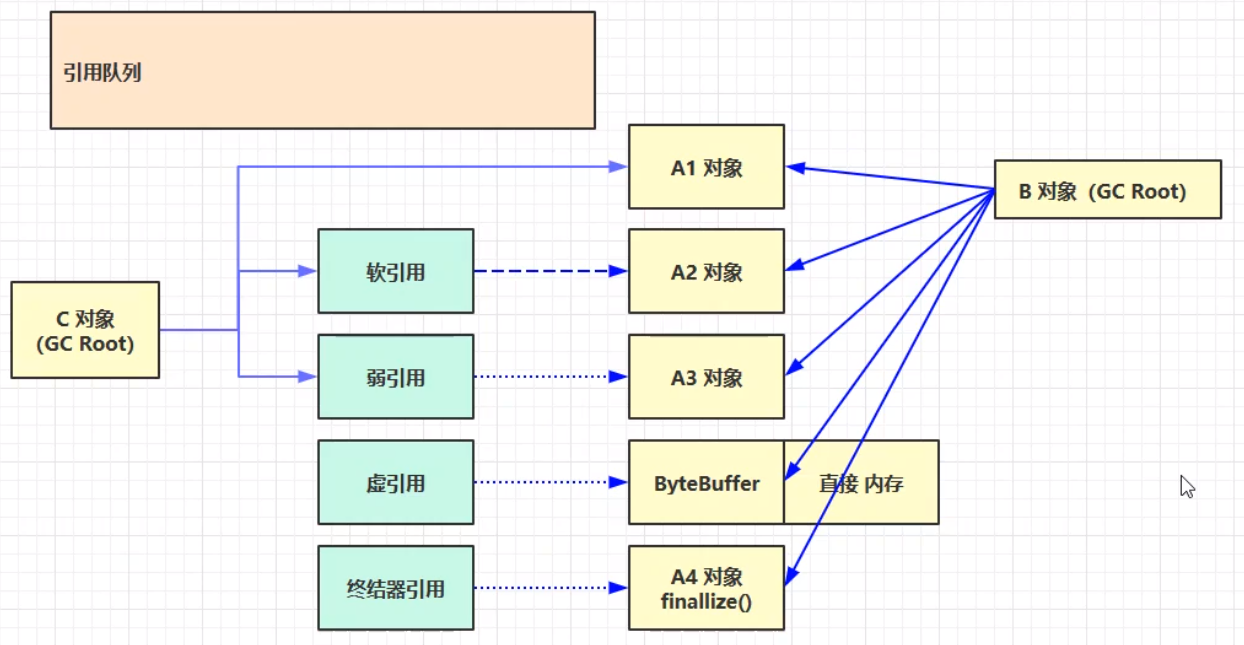
①只有当一个对象与其相连的所有强引用都断开,才能被垃圾回收。②当连接A2对象的强引用断开之后,若执行垃圾回收之后仍然发现内存不够用的时候,才会继续垃圾回收掉A2对象,也就是软引用的对象。③当指向A3对象的强引用断开之后,只要发生了垃圾回收,不管内存是都宽裕,A3(弱引用对象)都会被回收掉。④当软引用连接的对象(A2)被垃圾回收之后,软引用本身也已经成为了一个对象,这个时候会进入引用队列。同时,弱引用同理;二者在连接的对象被垃圾回收之后,都会进入引用队列。这是因为软引用和弱引用他们本身也需要占用一定的内存。如果想要对软引用和弱引用他们本身进行垃圾回收处理,可以借助引用队列找到他们,并做进一步的处理(遍历二者进行内存释放,相当于断开GC Root对象对他们的强引用,进行垃圾回收)。
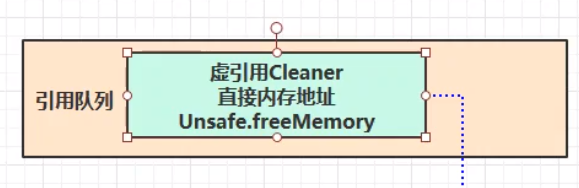
虚引用和终结器引用
此两者必须配合引用队列使用。当虚引用引用的对象被垃圾回收之后,虚引用就会被放入引用队列,从而间接地用一个线程来调用虚引用的方法,使用 unsafe.freeMemory()来释放直接内存。
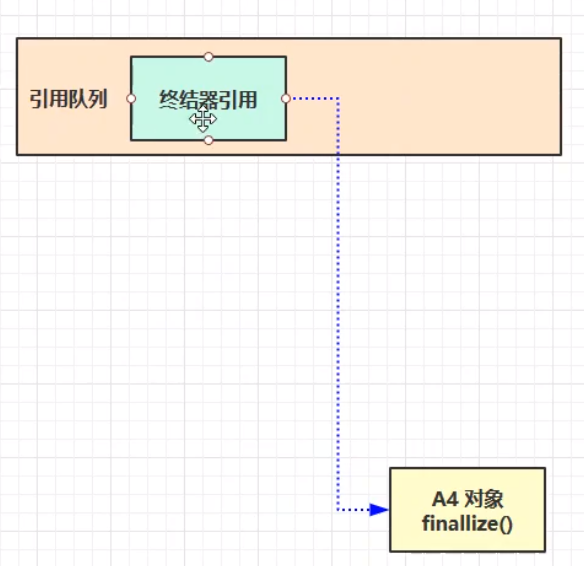
终结器引用:所有的Java对象都继承自Object父类,Object父类有一个finalize()方法。当A4对象的强引用被断开之后,将终结器引用放入引用队列中,然后由一个 优先级很低的线程去检查引用队列中是否存在终结器引用,如果存在终结器引用,则调用完A4的finalize方法,等调用结束,就可以等待下一次进行垃圾回收。其中,终结器引用效率很低:第一次回收时还不能真正的将其回收,需要二次进行回收;其次,要将终结器引用进行入队操作;再者,检测终结器引用的线程优先级很低,被执行的机会很少,可能会导致连接的方法的finalize方法迟迟得不到调用,无法结束自身的生命周期,所以导致该对象(A4)存在的生命周期中一直占用内存,短期内得不到释放。所以一般不推荐使用finalize方法释放内存。
# 引用的特点

软引用(SoftReference)
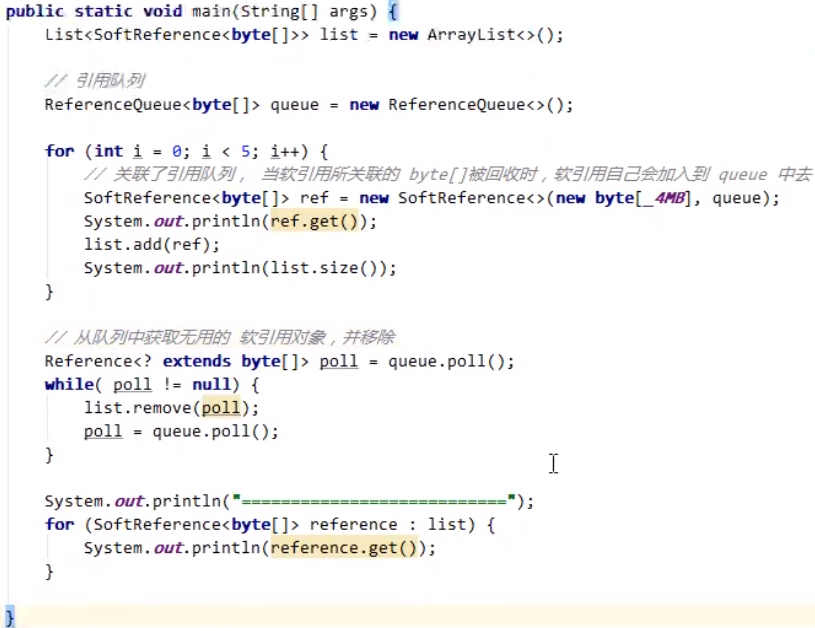
强引用和软引用的代码案例区别:其中,注释的部分即强引用;其余部分为软引用。


当软引用使用不到的时候,需要使用引用队列对软引用实现释放。使用**ReferenceQueuenew byte[_4MB], queue,关联之后,当软引用引用的对象被引用之后,对象需要回收时,会将软引用本身也加入到queue中去。整个过程,代码示例如下:
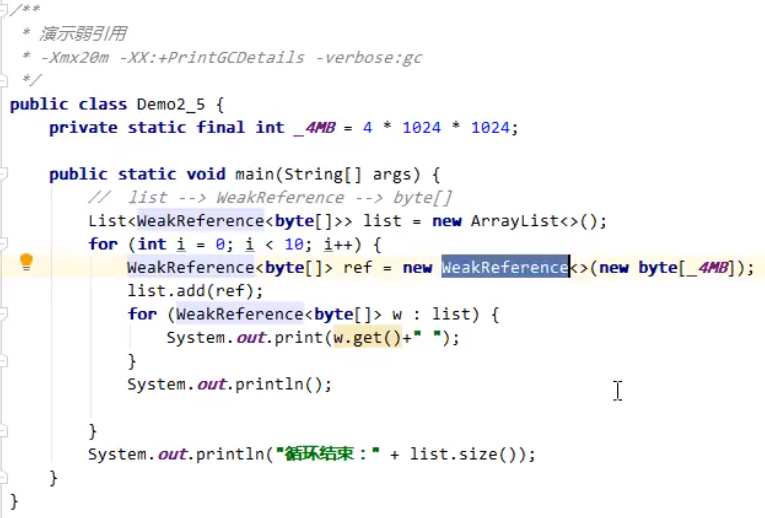
弱引用(WeakReference)
当弱引用连接的对象仅有弱引用时,垃圾回收时,无论内存是否充足,都会将弱引用所引用的对象进行垃圾回收。同样,也可以配合垃圾引用队列进行垃圾回收弱引用本身。
# 垃圾回收算法
# 标记清除(Mark Sweep)
顾名思义,标记清楚就是标记和清除两个步骤。第一个步骤,先标记可以被垃圾回收的对象(或者说需要被垃圾回收的对象)。这个步骤的思路:沿着GC Root的对象,从头到尾遍历所有对象,连着GC Root的对象则为强引用,不可被垃圾回收,其余的则根据情况进行标记,等待下一个步骤——清除。第二个步骤,清除标记的对象,将所有被标记的、可以被回收的对象进行垃圾回收。
其中,实现的细节问题:清除的步骤不是将对象的每个字节进行清零操作,而是将对象占用内存的起始地址记录在一个空闲的地址链表中。下次分配新的对象时,可以直接从空闲的地址链表中找,如果有足够的地址空间容纳这个对象,则为该对象分配空闲的地址空间。
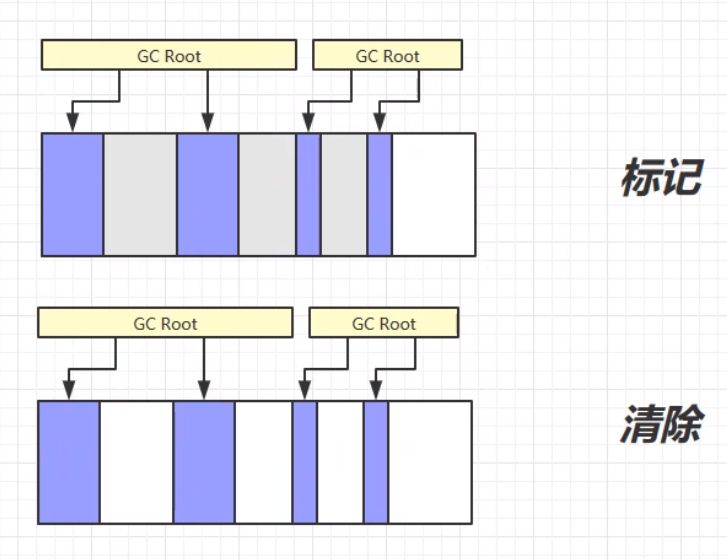
标记清除的优缺点:
优:标记清除的速度快,只需要对需要被垃圾回收的对象空间的起始地址做记录即可,所以标记清除的速度快。
缺:容易产生内存碎片。因为记录的是原对象的起始地址,原地址被标记记录之后,不会对地址空间进行整理,所以在对新对象进行地址分配的时候,容易造成内存的使用的不连续,导致大量空闲空间无法得到使用,造成内存使用的不充分不连贯。(页内碎片)
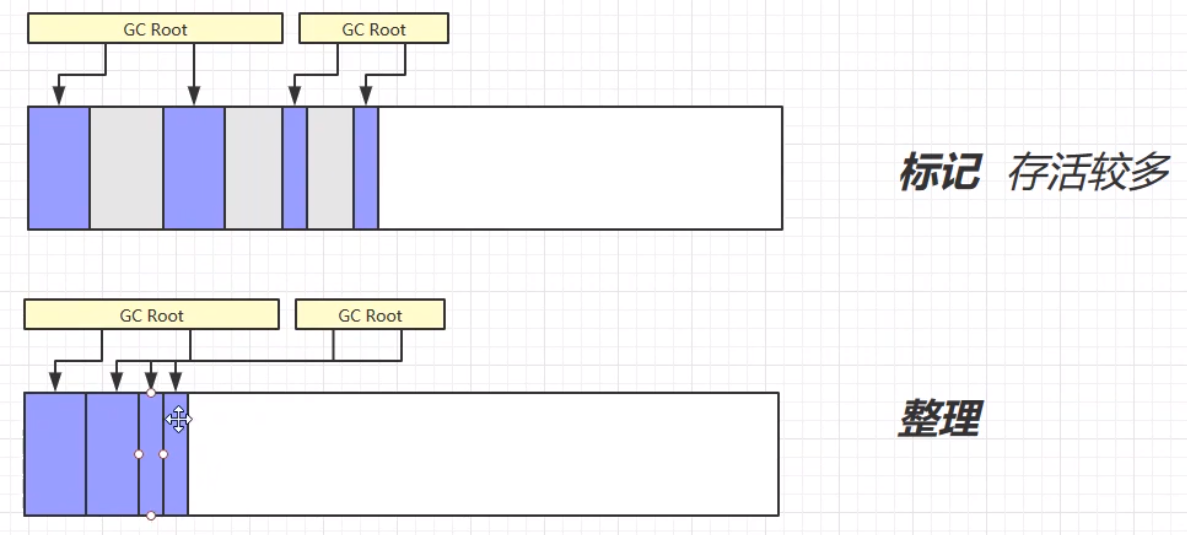
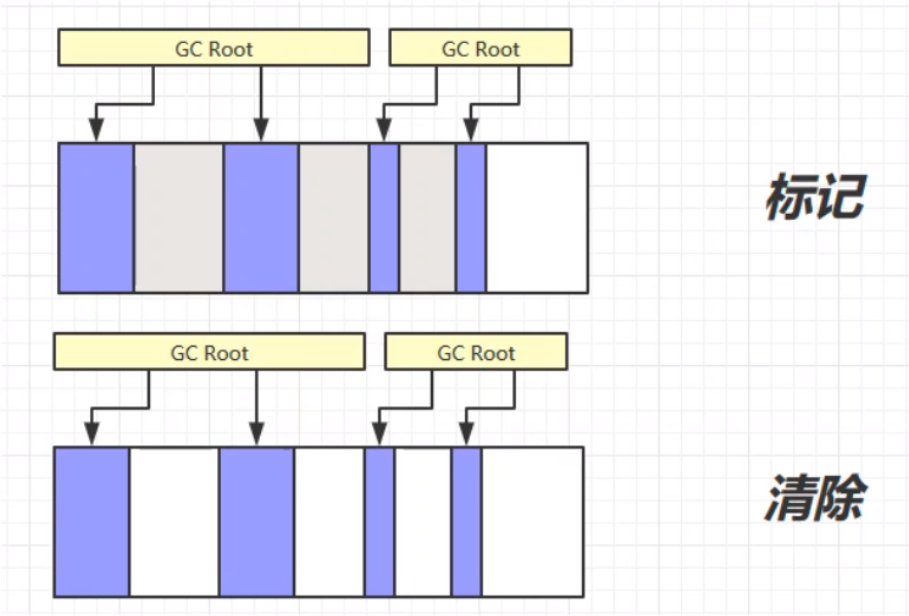
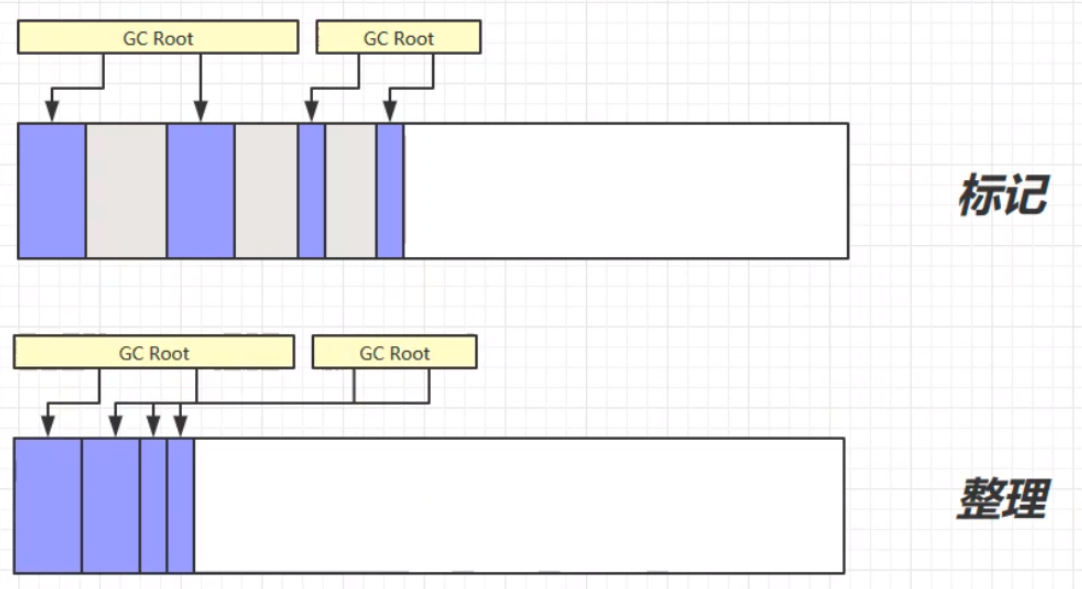
# 标记整理(Mark Compact)
标记整理算法,相比于之前的标记清除算法,在第二个清除的步骤中,不只是简单的清除,而是将清除之后不连续的内存空间进行整理,最后使得余留下来的对象占据的还是连续的内存空间。
标记整理的优缺点:
优:相较于标记清除,不会产生内存碎片。
缺:由于涉及对象空间的移动,使得整个过程更加复杂繁琐。内存区块的拷贝移动、内存地址的改变等,这些问题更加复杂,需要更多的工作量,所以速度更慢。
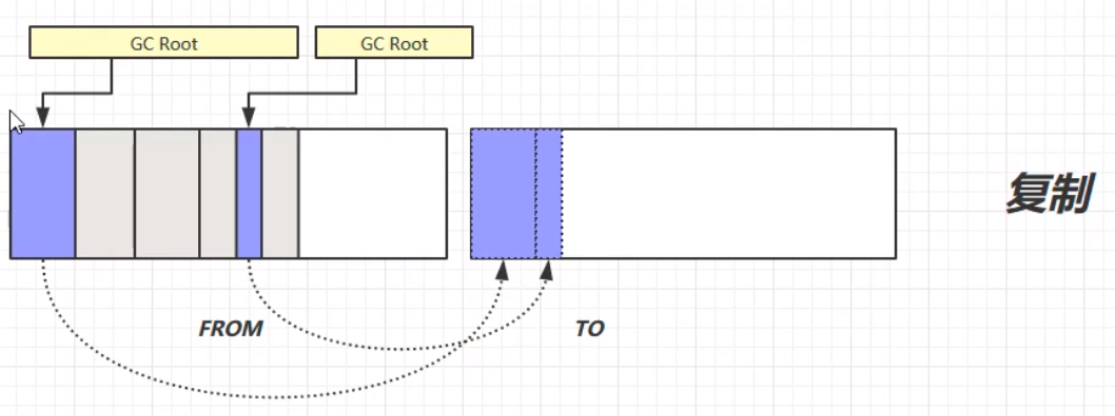
# 复制(Copy)
复制算法,首先将GC Root的强引用对象赋值到TO区域中;其次,将FROM中的所有需要垃圾回收的对象进行垃圾回收;之后,交换FROM和TO的位置;最终,垃圾回收完成。演示步骤如下:
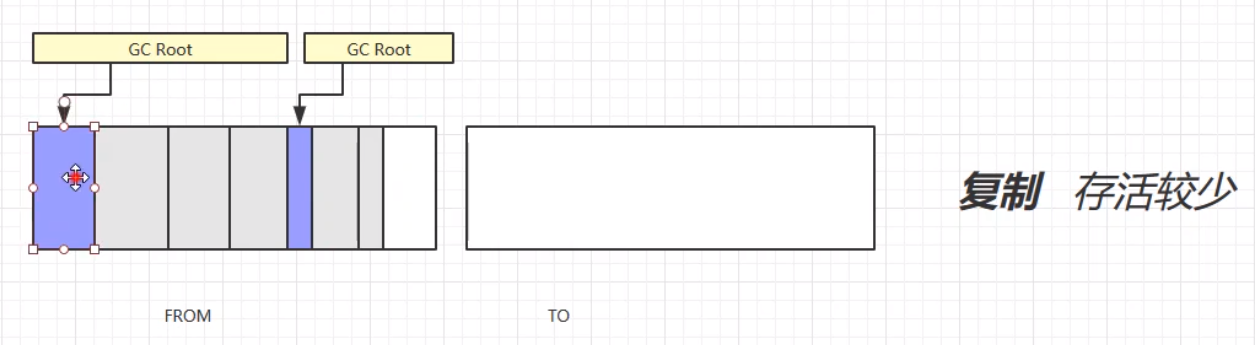
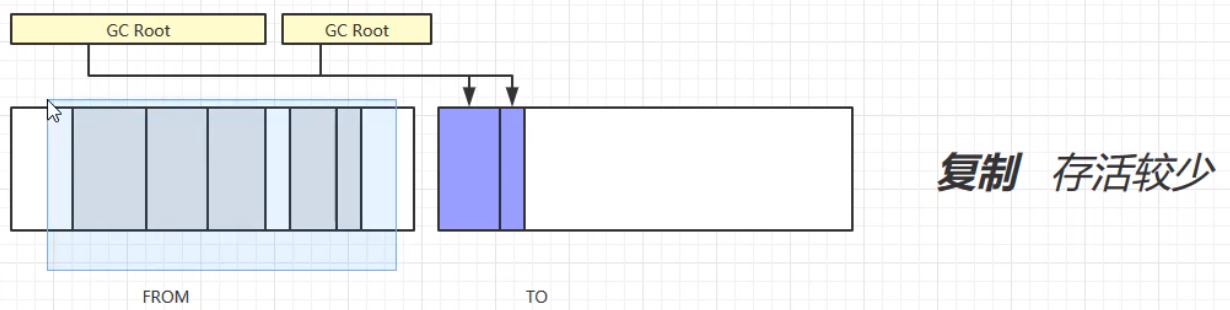
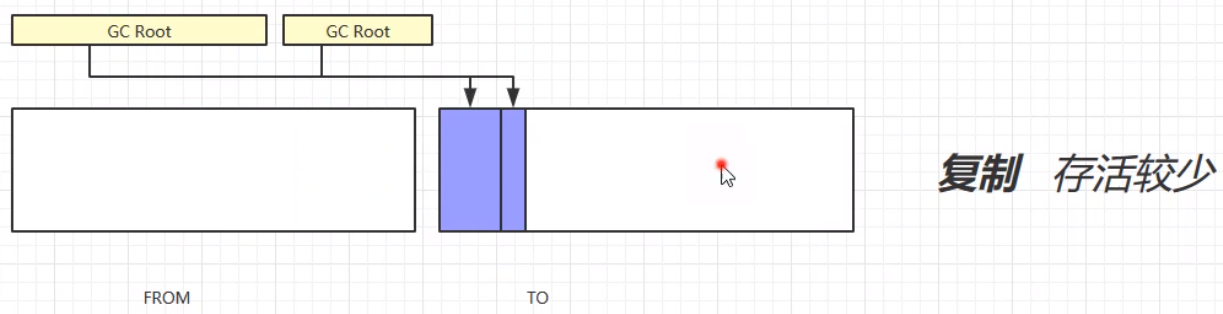
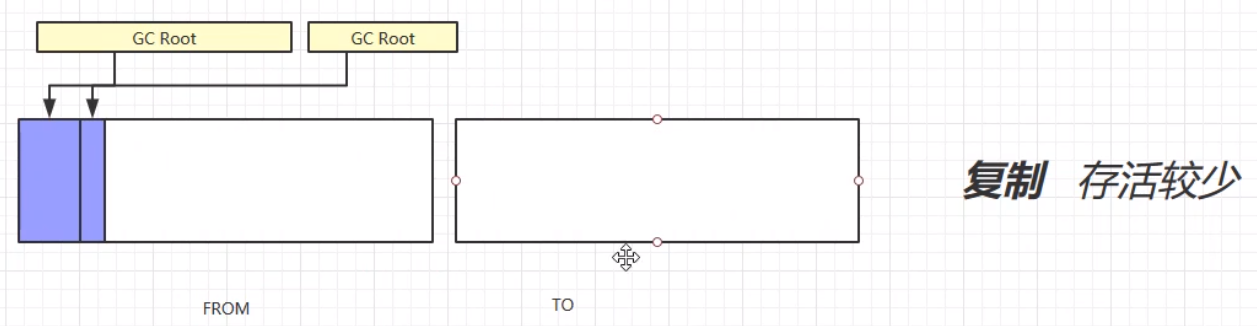
复制算法的优缺点:
优:不会产生内存碎片,最终形成连贯的空闲空间。
缺:在进行垃圾回收的时候,会占用双倍的内存空间,且工作量也比较大。
# 总结
标记清除算法(Mark Sweep)
- 速度较快
- 会造成内存碎片
标记整理算法(Mark Compact)
- 速度慢
- 没有内存碎片
复制算法(Copy)
- 不会有内存碎片
- 需要占用双倍内存空间
# 分代回收
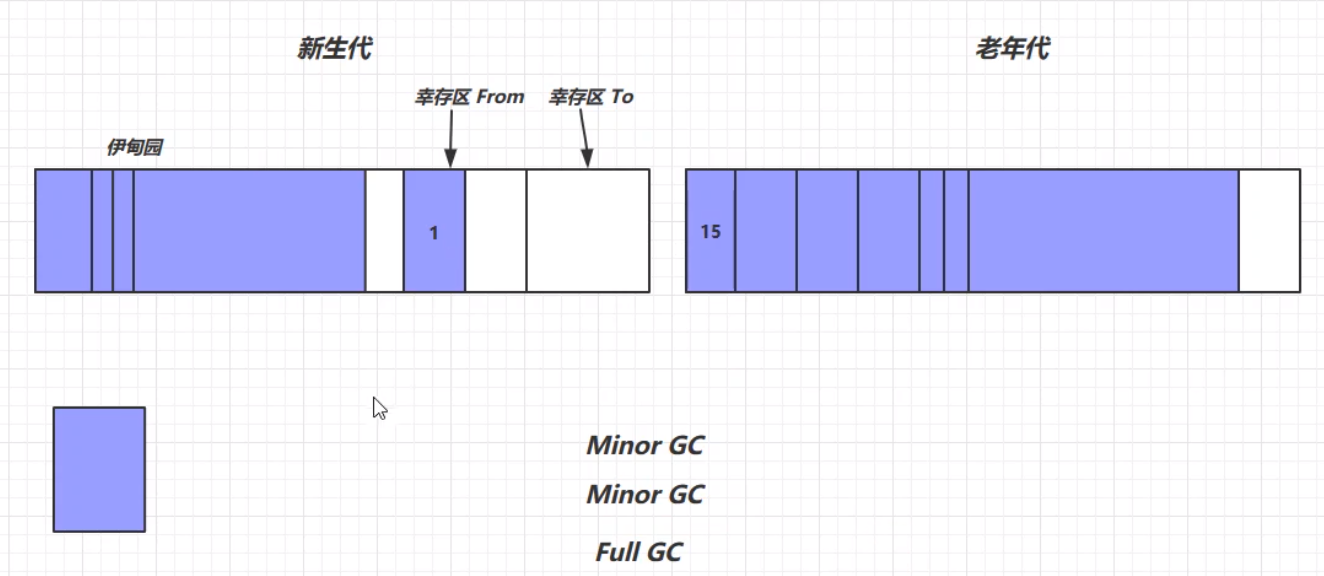
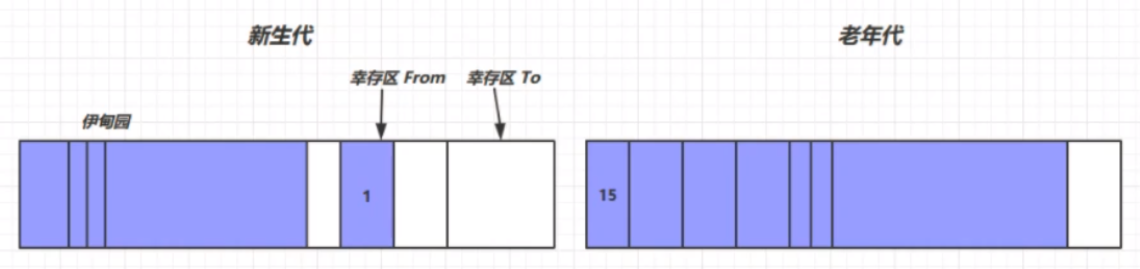
垃圾回收中,有新生代、老年代、伊甸园(Eden)、幸存区(FROM)、幸存区(TO)的概念。
我们一般将需要长时间使用的对象放在老年代中,把那些用完即丢的对象放在新生代中。针对不同对象的生命周期,为他们制定不同的垃圾回收策略。这就是创造分代回收的原因。
首先,新生代的结构如下所示:
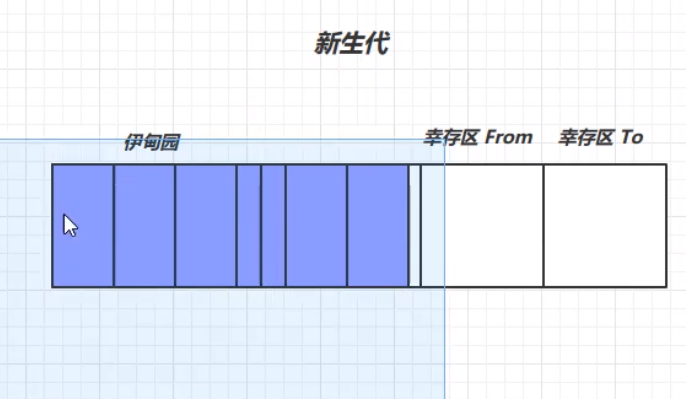
我们将每次新创建的对象存放在伊甸园中。但是,新生代中伊甸园的内存是有限的,当伊甸园的内存不够时,便会触发新生代的一次垃圾回收,回收处理伊甸园中的垃圾,此次垃圾回收称之为Minor GC。
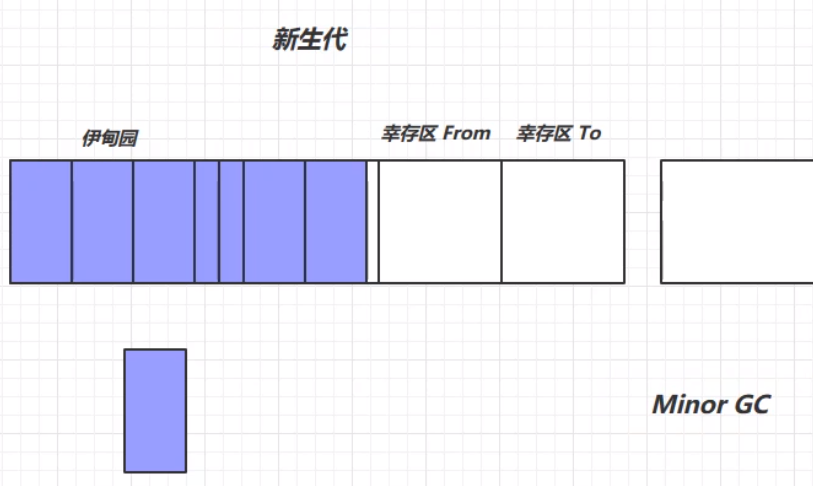
此次垃圾回收,利用复制算法,将幸存的对象放入幸存区TO中,并将这些对象的生命周期进行+1的操作,表示这些对象已经经历了一次垃圾回收,但是幸存下来,并没有被回收掉。然后根据复制算法,将From和To的位置交换,完成一次垃圾回收。
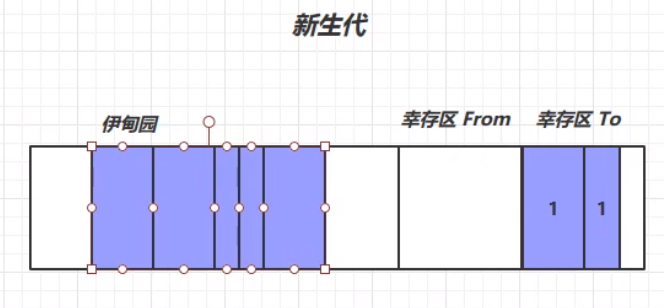
此时上图中被标记的对象就会被Minor GC回收掉。第二过程中,等到伊甸园中的对象再次内存不足时,就会再次出发Minor GC进行垃圾回收。但是,此次Minor GC不光要扫描伊甸园中的对象,还需要对之前幸存区From中的对象进行扫描,看是否存在需要被垃圾回收的对象。最终幸存的对象生命周期+1,放在幸存区From中。
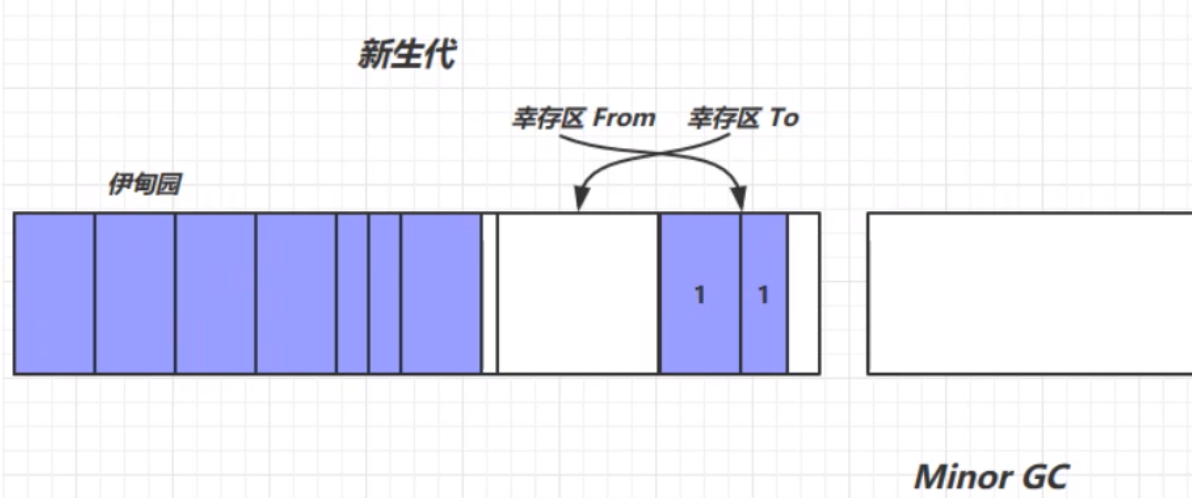
在经历了第二轮的Minor GC之后,可能的对象存活情况如下:
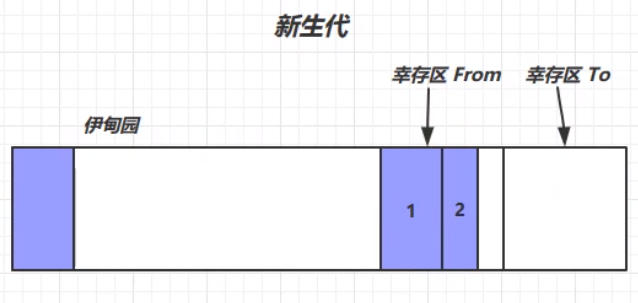
在经历多次Minor GC之后,可能存在一些对象的生命周期变得比较长(超过一定阈值),这个时候就出现了晋升——将这些生命周期较长的对象存放在老年代区(最大生命周期是15——4bit(1111))。因为老年代发生GC的频率相对新生代来说较低,所以生存周期更长的对象放在老年代区能够减少扫描的次数,提高一定的工作效率。
但是,当新生代的伊甸园以及From区、老年代区都无法存放下新生成的对象时,这个时候就会触发一次Full GC。
分代垃圾回收的一些特点:
- 对象首先分配在伊甸园区域
- 新生代空间不足时,触发minor gc,伊甸园和from存活的对象使用copy复制到to中,存活的对象年龄加一并且交换from和to
- minor gc会引发stop the world,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
- 当对象寿命超过阈值时,会晋升至老年代,最大寿命是15 (4bit)
- 当老年代空间不足,会先尝试触发minor gc,如果之后空间仍不足,那么触发full gc,STW的时间更长
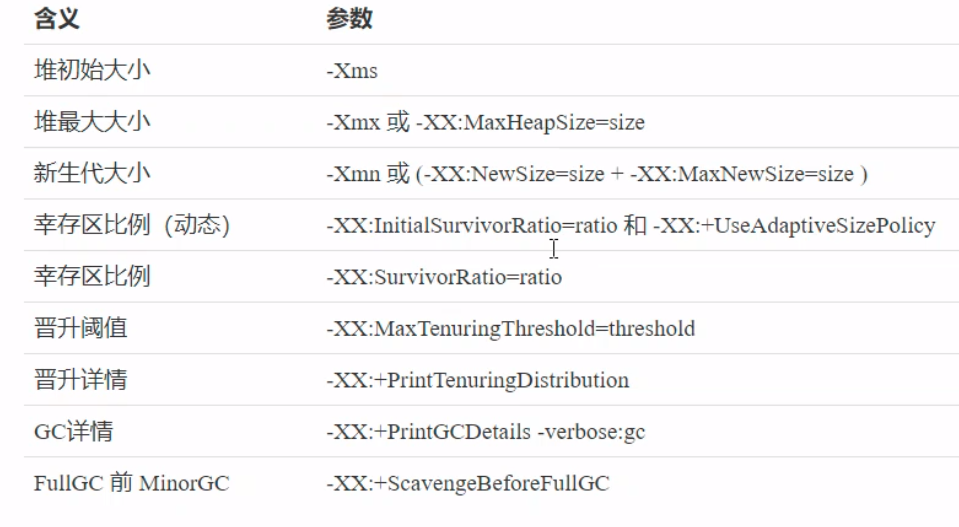
# 相关参数